-
[QueryDSL] Entity 쿼리 로직의 데이터베이스 접근 횟수를 최소화해 리소스 생성 동작 성능 개선하기Today I Learned 2023. 6. 23. 01:50
최종보스
프로젝트를 진행하면서 코드를 구현하는 데 가장 많은 시간을 써야 했고, 가장 마지막까지 방치했던 부분은 목록과 관련된 리소스를 반환하는 로직이었다.
하나의 리소스를 조합하는 데 여러 Entity들이 필요한 동작이 있었다. 경기 목록이나 검색 결과와 같은 리소스를 반환하는 식의 동작들이었는데, 본 글에서는 검색 결과 리소스를 구성하는 예시를 살펴보려 한다.기존에는 경기 목록을 구성하는 리소스 하나를 생성하기 위해 다음의 Entity들이 필요했다.
- Post 하나
- Place 하나
- Post, Place와 연결된 Game 하나
- Game과 연결된 Register 여러 개경기에 참가하는 사용자를 키워드로 경기 목록을 검색하는 Service는 다음과 같은 로직으로 작성되어 있었다. 비록 Post Entity가 Game Entity에 통합되기는 했지만, 그럼에도 불구하고 여전히 복잡도가 상당히 높기 때문에 코드로는 이해하기 난해할 수 있어 주석으로 대체했다.
// services/game/SearchGamesByApplicantService.java @Service @Transactional(readOnly = true) public class SearchGamesByApplicantService implements SearchGamesStrategy { private final UserRepository userRepository; private final RegisterRepository registerRepository; private final GameRepository gameRepository; private final PlaceRepository placeRepository; public SearchGamesByApplicantService(UserRepository userRepository, RegisterRepository registerRepository, GameRepository gameRepository, PlaceRepository placeRepository) { this.userRepository = userRepository; this.registerRepository = registerRepository; this.gameRepository = gameRepository; this.placeRepository = placeRepository; } @Override public List<GameSearchResultDto> search(User user, String keyword) { // 1. 주어진 키워드를 포함한 사용자(User)를 모두 찾는다. // 2. 찾은 모든 사용자 컬렉션을 순회한다. // a. 각 사용자의 참가신청 상태인 신청기록(Register)들을 모두 찾는다. // b. 찾은 모든 신청기록 컬렉션을 순회한다. // i. 각 신청기록에 해당하는 경기(Game)를 찾는다. // ii. 경기에 해당하는 장소(Place)를 찾는다. // iii. 경기에 신청한 모든 신청기록들을 찾는다. // iv. 경기, 장소, 신청기록들을 조합해 리소스를 생성한다. // 3. 생성된 모든 리소스들을 컬렉션으로 반환한다. } }이 로직에서 확인할 수 있는 가장 큰 두 가지의 문제점을 짚어보자.
단위 테스트가 굉장히 복잡해진다
코드를 작성하면서 가장 빠르게 피부로 느낄 수 있었던 문제점은, 이 로직대로 작성된 소스코드에 대해 예외가 발생하지 않으면서 최소한의 의미있는 결과를 확인하는 단위 테스트 코드를 작성하는 것 자체부터가 굉장히 어려웠다는 것이다.
해당 로직에 대한 단위 테스트 코드를 작성하기 위해서는 Service 클래스의 외부로부터 주입되는 각 repository에 대해, find() 계열 메서드들을 실행했을 때 반환받을 수 있는 값들을 세팅해줘야 했다. 문제는 로직 설명을 보면 알 수 있듯이, repository에 접근하는 동작이 2중 반복문으로 이루어지고 있다. 어느정도 사실감있는 테스트 코드를 작성한다고 할 때, 설정해야 하는 MockUp들을 살펴보자.- 검색 기록을 만족하는 모든 User를 찾았을 때 3개의 User가 반환된다.
- 1번 User의 Register들을 찾았을 때, 2개의 Register들이 반환된다.
- 1번 User의 1번 Register의 Game을 찾았을 때, 특정 Game이 반환된다.
- 1번 User의 1번 Register의 Game의 Place를 찾았을 때, 특정 Place가 반환된다.
- 1번 User의 1번 Register의 Game의 모든 Register들을 찾았을 때, 3개의 Register들이 반환된다.
- 1번 User의 2번 Register의 Game을 찾았을 때, ...
- ...
- ...
- ...
- 3번 User의 m번 Register의 Game의 모든 Register들을 찾았을 때, n개의 Register들이 반환된다.반환되는 Entity들은 모두 테스트 코드 내에서 생성자로 직접 생성해줘야 하는 객체들이다. 따라서 주입되는 Repository들에 대해, 특정 id 값으로 조회를 시도했을 때 반환할 Entity들을 모두 개별적으로 세팅해줘야 한다. MockUp 데이터의 양이 많아지는 것을 떠나서, 매 반복마다 호출되는 쿼리 메서드에서 반환할 Entity들을 서로 조금씩 다르게 구성해줘야 하기 때문에 MockUp 데이터를 세팅하는 로직 자체가 대단히 복잡해지게 되고, 테스트 코드를 이해하기 어렵게 만들어 테스트 코드의 유지보수가 어려워지게 된다.
지나치게 많은 데이터베이스 서버와의 통신으로 인해 성능이 저하된다
애플리케이션이 In-memory 방식으로 데이터베이스를 구성하지 않는 이상 데이터베이스는 서버 애플리케이션과는 별개로 존재하게 되고, 특정 로직에서 데이터를 쿼리하기 위해서는 네트워크 통신을 통해 데이터베이스에 접근해야 한다. 위의 로직에서 사용자를 찾았을 때 5,000개의 User Entity를 반환한다고 해 보자. 각 사용자에 대해 1개의 Register만 존재한다고 해도, 한 번의 Service 메서드를 수행하는 과정에서 데이터베이스에 접근해야 하는 횟수는 15,000번이다.
15,000번이나 수행해야 하는 애플리케이션 외부와의 통신은 성능에 얼마나 악영향을 끼칠 수 있을까? 통합 테스트를 작성해 확인해보았다.
// services/game/SearchGamesByApplicantServiceExecutionTimeTest.java // 두 개 이상의 Layer의 상호작용과, 애플리케이션 외부와의 통신을 테스트하기 위해 // ApplicationContext를 생성하는 @SpringBootTest 어노테이션을 부여했다. @SpringBootTest @Testcontainers @Transactional class SearchGamesByApplicantServiceExecutionTimeTest { // 특정 로직을 수행하기 위해 주입되는 객체들은 모두 실제로 동작해야 한다. // @Autowired 어노테이션을 붙여 의존성을 주입받았다. @Autowired private UserRepository userRepository; @Autowired private RegisterRepository registerRepository; @Autowired private GameRepository gameRepository; @Autowired private PlaceRepository placeRepository; // In-memory가 아닌 애플리케이션 외부에 존재하는 데이터베이스 서버와 // 통신하도록 하기 위해 testcontainer를 정의했다. @Container private final PostgreSQLContainer<?> container = new PostgreSQLContainer<>("postgres:latest"); @Autowired private JdbcTemplate jdbcTemplate; @Autowired private EntityManager entityManager; private String keyword; private int number; @BeforeEach void setUp() { clearDatabase(); keyword = "사용자"; number = 5000; setUpNumberOfEntities(keyword, number); } @AfterEach void teardown() { clearDatabase(); } private void clearDatabase() { jdbcTemplate.update("DELETE FROM registers"); jdbcTemplate.update("DELETE FROM games"); jdbcTemplate.update("DELETE FROM places"); jdbcTemplate.update("DELETE FROM users"); } private void setUpNumberOfEntities(String name, int count) { for (int id = 1; id <= count; id += 1) { // User, Place, Game, Register Entity들을 // count 개수만큼, 조건에 맞게 JdbcTemplate을 통해 삽입했다. } } private void testWithStrategy(SearchGamesStrategy strategy) { // 메서드 수행 결과를 측정하기 위해 총 네 번의 테스트를 수행했다. int iterationCount = 4; double[] times = new double[iterationCount]; // 로직 자체에 오류가 없는지 확인하고 // 데이터베이스와의 연결을 최초로 수립시키기 위해 // 로직 수행 시간을 측정하기 전, 한 번의 테스트를 별도로 수행했다. List<GameSearchResultDto> gameSearchResultDtos = strategy.search(null, keyword); assertThat(gameSearchResultDtos).isNotNull(); assertThat(gameSearchResultDtos).hasSize(number); IntStream.range(0, iterationCount) .forEach(i -> { // 테스트 수행 시간을 측정했다. StopWatch stopWatch = new StopWatch(); stopWatch.start(); strategy.search(null, keyword); stopWatch.stop(); times[i] = stopWatch.getTotalTimeSeconds(); // EntityManager의 1차 캐시에서 Entity를 참조해 // 수행 시간이 단축되는 경우를 방지하기 위해 // 테스트가 종료된 후에는 캐시에 저장된 데이터들을 소거시켰다. entityManager.getEntityManagerFactory() .getCache() .evictAll(); }); System.out.print("\n\n\n"); System.out.println("수행 시간"); IntStream.range(0, iterationCount) .forEach(i -> System.out.println(times[i])); System.out.print("\n\n\n"); } @Test void searchGames() { SearchGamesByApplicantService searchGamesByApplicantService = new SearchGamesByApplicantService( userRepository, registerRepository, gameRepository, placeRepository ); testWithStrategy(searchGamesByApplicantService); } }데이터베이스를 testcontainer를 이용해 애플리케이션 외부의 container에 두고, 검색 조건과 일치하는 5,000개의 User Entity와 연관된 데이터들을 쿼리한 뒤 리소스를 생성해 반환하는 전체 로직을 수행하도록 한 테스트 결과는 다음과 같다. 측정 기준은 초이다.
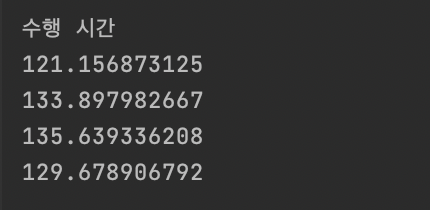
평균적으로 120초 가량...의 수행 시간이 소요된 것을 확인할 수 있다.
한 번의 쿼리만으로 모든 데이터들을 가져올 수 있다면?
두 가지 문제들은 단 한 번의 데이터베이스 접근으로 필요한 모든 Entity들을 쿼리해오는 방식으로 개선해 해결할 수 있다. 필요한 모든 데이터들을 한 번에 쿼리하기 위해 이전에 과제를 수행하면서 사용했던 QueryDSL을 도입해보기로 했다.
QueryDSL 사용 환경 세팅은 다음의 글을 참고할 수 있다.
JPA에서 QueryDSL을 사용해 Join이 필요한 쿼리 수행하기
JPA를 이용해 두 개 이상의 테이블을 Join한 뒤, 조건에 맞는 Column을 쿼리하려면 쿼리 메서드를 어떻게 작성해야 할까? 이전에 개인 프로젝트를 진행할 때 모든 채팅 메시지 Entity 중 특정 채팅방의
innu3368.tistory.com
사용될 Entity들의 예시는 다음과 같다. 연관관계가 있거나, 쿼리 시 조건에 필요한 Column을 표현하기 위한 필드만을 포함시켰다.
// models/game/Game.java @Entity public class Game { @Id @GeneratedValue private Long id; private Long placeId; // ACTIVE, DELETED @Enumerated(EnumType.STRING) private GameStatus status; }// models/place/Place.java @Entity public class Place { @Id @GeneratedValue private Long id; }// models/user/User.java @Entity public class User { @Id @GeneratedValue private Long id; private String name; }// models/register/Register.java @Entity public class Register { @Id @GeneratedValue private Long id; private Long gameId; private Long userId; // APPLIED, ACCEPTED, CANCELED, REJECTED @Enumerated(EnumType.STRING) private RegisterStatus status; }하나의 검색 결과 리소스를 생성하는 데 필요한 Entity들을 다시 한 번 정리해보자.
- Place 하나
- 해당 Place와 연결된 Game 하나
- 해당 Game과 연결된 모든 Register하나의 Entity 그룹에 포함되는 Entity들이 3개 이상이므로 쿼리 메서드의 반환형을 Map<Key, Value> 형태만으로 나타내기에는 무리가 있었다. 이들을 적절하게 표현할 수 있는 방법을 고민했다. 쿼리를 수행하는 영역은 애플리케이션과 데이터베이스를 연결하는 Infrastructure Layer이고, 쿼리 메서드의 역할은 Application Layer에 데이터를 전달하는 것이므로, DTO 객체를 정의해 데이터 전달에 사용해보기로 했다. 일단은 단순 POJO 형태의 객체로 정의했다.
// dtos/query/game/GameSearchByApplicantQueryResultDto.java public class GameSearchByApplicantQueryResultDto { private final Game game; private final Place place; private final List<Register> registers = new ArrayList<>(); public GameSearchByApplicantQueryResultDto(Game game, Place place, List<Register> registers) { this.game = builder.game; this.place = builder.place; this.registers.addAll(registers); } public Game getGame() { return game; } public Place getPlace() { return place; } public List<Register> getRegisters() { return registers; } }모든 Entity들을 쿼리하기 위한 쿼리 로직은 다음과 같이 작성했다.
// repositories/GameSearchRepositoryImpl.java import static kr.megaptera.smash.models.game.QGame.game; import static kr.megaptera.smash.models.place.QPlace.place; import static kr.megaptera.smash.models.register.QRegister.register; import static kr.megaptera.smash.models.user.QUser.user; @Repository public class GameSearchRepositoryImpl implements GameSearchRepository { private final JPAQueryFactory jpaQueryFactory; public GameSearchRepositoryImpl(JPAQueryFactory jpaQueryFactory) { this.jpaQueryFactory = jpaQueryFactory; } @Override public List<GameSearchByApplicantQueryResultDto> findAllSearchResultsByApplicant( String keyword ) { List<Tuple> tuples = jpaQueryFactory // Game 테이블에 Place, Register 테이블을 join시켜 // 하나의 Tuple에 서로 연관관계를 갖는 // Game, Place, Register 하나씩을 연결했다. // 이때 검색 키워드를 바탕으로 사용자를 식별해야 하므로 // User 테이블도 join시켜 Register와 User를 연결시켰다. .select(game, place, register) .from(game) .rightJoin(place).on(place.id.eq(game.placeId)) .rightJoin(register).on(register.gameId.eq(game.id)) .rightJoin(user).on(register.userId.eq(user.id)) // 조건에 해당되는 Entity들을 filter한다. // contains(String) 연산은 "%" + String + "%"을 수행한다. .where(user.name.value.contains(keyword) .and(game.status.eq(GameStatus.ACTIVE)) .and(register.status.eq(RegisterStatus.APPLIED))) .orderBy(user.name.value.asc()) .fetch(); // 각 Tuple에는 하나씩의 Game, Place, Register끼리만 연결되어 있다. // 그러나 반환해야 하는 Entity 그룹에는 // 하나의 Game과 연결된 모든 Register들이 포함되어야 하므로 // 모든 Tuple들을 순회하면서 각 Game의 모든 Register들을 집계한다. Map<Game, List<Register>> gameAndRegisters = new HashMap<>(); tuples.forEach(tuple -> { Game gameQueried = tuple.get(game); Register registerQueried = tuple.get(register); gameAndRegisters.computeIfAbsent( gameQueried, key -> new ArrayList<>() ).add(registerQueried); }); // 모든 Tuple들을 다시 한 번 순회하면서 // 각 Game, Place, List<Register>들을 DTO로 그룹화하고, // 모든 DTO들을 List로 묶어 반환한다. return tuples.stream() .map(tuple -> { Game gameQueried = tuple.get(game); Place placeQueried = tuple.get(place); return new GameSearchByApplicantQueryResultDto.Builder() .game(gameQueried) .place(placeQueried) .registers(gameAndRegisters.get(gameQueried)) .build(); }) .toList(); } }해당 Repository를 주입받아 검색 결과 리소스를 생성하는 Service interface의 구현은 다음과 같다.
// services/game/SearchGamesByApplicatnWithQueryDslService.java @Service @Transactional(readOnly = true) public class SearchGamesByApplicantWithQueryDslService implements SearchGamesStrategy { // GameSearchRepository interface를 extends한 // GameRepository를 주입받는다. private final GameRepository gameRepository; public SearchGamesByApplicantWithQueryDslService(GameRepository gameRepository) { this.gameRepository = gameRepository; } @Override public List<GameSearchResultDto> search(User user, String keyword) { // 한 번의 쿼리를 수행해 필요한 모든 Entity들을 가져온다. List<GameSearchByApplicantQueryResultDto> queryResultDtos = gameRepository.findAllSearchResultsByApplicant(keyword); Set<Game> convertedGames = new HashSet<>(); return queryResultDtos.stream() .map(queryResultDto -> { Game game = queryResultDto.getGame(); Place place = queryResultDto.getPlace(); List<Register> registers = queryResultDto.getRegisters(); // 이미 리소스로 변환한 Game이 다시 주어질 경우 // 무시하기 위해 null을 반환한다. if (convertedGames.contains(game)) { return null; } convertedGames.add(game); return game.toGameSearchResultDto( user, place, registers, "applicant" ); }) // map 결과에 null이 포함된 경우 제외시킨다. .filter(Objects::nonNull) .toList(); } }이전의 문제들이 개선되었는가?
이전의 Service 로직과 지금의 가장 큰 차이점들은 무엇일까?
- Service에 주입되는 Repository interface들이 하나로 줄었다. RepositoryImpl에서 로직에 필요한 모든 Entity들의 테이블에 접근할 수 있기 때문이다.
- 2중 반복문으로 구성되었던 Entity 쿼리 로직이 하나의 쿼리 메서드로 변경되었다.
이런 변경점들을 바탕으로 이전의 문제들이 해결되었는지 살펴보도록 하자.
단위 테스트를 작성하기 수월해졌는가?
단 한 번의 쿼리 메서드로 모든 데이터를 가져오기 때문에, 테스트 코드에서도 해당 한 번의 쿼리 메서드를 수행했을 때 반환되는 DTO만을 정의한 뒤 MockUp으로 전달해주면 되게 되었다.
테스트 케이스에 따라 MockUp 데이터의 크기는 여전히 클 수 있지만, 높은 복잡성을 야기했던 이전 테스트 코드와는 달리 이제는 하나의 DTO에 모든 Entity 그룹을 나타내주기만 하면 되기 때문에 테스트 코드의 복잡성 자체를 많이 감소시킬 수 있다는 개선점이 도출되었다.
성능이 개선되었는가?
개선한 Service의 메서드를 같은 데이터셋을 이용하는 통합 테스트에서 수행시켜 테스트에 걸리는 수행 시간을 측정했다.
// services/game/SearchGamesByApplicantServiceExecutionTimeTest.java // 다음의 테스트 메서드를 추가한다. @Test void searchGamesWithQueryDsl() { SearchGamesByApplicantWithQueryDslService searchGamesByApplicantWithQueryDslService = new SearchGamesByApplicantWithQueryDslService( gameRepository ); testWithStrategy(searchGamesByApplicantWithQueryDslService); }테스트 결과는 다음과 같다. 측정 기준은 초이다.

동일한 데이터셋을 바탕으로 테스트를 수행했을 때, 개선의 정도를 언급하는 게 민망한 수준으로 성능이 개선된 것을 확인할 수 있었다.
아쉬웠던 점
RepositoryImpl의 쿼리 로직을 살펴보면, 순수 쿼리문뿐만 아니라 쿼리 결과를 별도의 로직을 통해 반환에 적절한 형태로 정제하는 로직이 같이 존재하는 것을 확인할 수 있다.
본래는 쿼리 로직을 Projection 개념을 활용해 순수 쿼리문만으로 한 번에 DTO를 생성해 반환하는 것을 계획했었다. DTO 객체를 단순히 DTO 객체만으로 활용하는 것이 아닌 Projection을 목적으로 하는 객체로 활용하고자 했던 것이다. 이를 위해 쿼리문의 SELECT 구문에 인자로 DTO의 생성자가 전달받는 인자 타입들의 클래스 타입들을 전달하는 Projection.constructor() 메서드를 호출하고, GROUP BY 구문을 쿼리문에 추가했었다.
// repositories/GameSearchRepositoryImpl.java // 처음 작성했었던 쿼리 메서드는 다음과 같다. import static kr.megaptera.smash.models.game.QGame.game; import static kr.megaptera.smash.models.place.QPlace.place; import static kr.megaptera.smash.models.register.QRegister.register; import static kr.megaptera.smash.models.user.QUser.user; @Override public List<GameSearchByApplicantQueryResultDto> findAllSearchResultsByApplicant( String keyword ) { return jpaQueryFactory .select(Projections.constructor( GameSearchByApplicantQueryResultDto.class, game, class, register )) .from(game) .leftJoin(place).on(place.id.eq(game.placeId)) .leftJoin(register).on(register.gameId.eq(game.id)) .leftJoin(user).on(register.userId.eq(user.id)) .where(user.name.value.contains(keyword) .and(game.status.eq(GameStatus.ACTIVE)) .and(register.status.eq(RegisterStatus.APPLIED))) .groupBy(user, game, register) .orderBy(user.name.value.asc()) .fetch(); }Game Entity에 맞게 Register들이 그룹화되었기 때문에, DTO를 Projection 방식으로 생성할 때 Game Entity에 맞는 List<Register>의 형태로 그룹화되어 삽입되는 동작을 기대했으나 기대대로 동작되지 않았다. DTO는 생성되었지만, 반환된 DTO는 특정 Tuple에 Game Entity와 join된 단일 Register Entity만이 존재했다.
이에 대해 찾아본 바로는, GROUP BY 개념은 집계된 Entity들의 개별 Entity 자체에 대한 정보를 상세하게 표현하는 것이 아니라 집계된 Entity들의 개수만을 카운트하기 때문에 의도한 대로 동작할 수 없다는 것으로 일단 확인했다.References
- Querydsl으로 안전한 쿼리 작성하기 + DataJPA
'Today I Learned' 카테고리의 다른 글
[QueryDSL] WHERE 절에 서브쿼리 전달하기 (0) 2023.06.25 [Java] interface 상속, default method 개념을 적용해 여러 interface들 간의 공통 기본 동작 정의하기 (0) 2023.06.24 [Spring] ApplicationEventPublisher를 활용해 Event 기반 동작 구현하기 (0) 2023.06.20 [Java][JPA] 추상 클래스 개념을 적용해 알림 객체 설계 개선하기 (0) 2023.06.17 [Java] Reflection API란 무엇인가? (0) 2023.05.27